散列表
散列表的内部机制:实现、冲突和散列函数。(散列函数 + 数组 = 散列表)
举例:
一间商店,客人来买东西结账,你作为服务员需要在一个小本本中查找价格。如果它不是按字母排序的,你可能一行一行看,即简单查询O(n);如果它内容是按字母排序的,可使用二分法查找出价格O(log n)。
虽然二分法已经很快了,但当商品数量非常多的时候,还是需要等上几秒时间;
有没有一位可以记下所有商品价格的收银员呢,只要告诉她什么商品,则立马知道价格。——散列表
散列表也叫散列映射、映射、字典和关联数组,数据是以 [键,值] 的形式保存,键不能重复。查询速度:O(1)
散列函数
它是一个函数,无论你给它什么数据,它都还你一个数字,即“将输入映射到数字”。
注意
它必须是一致的,你输入某一个值它必须有唯一固定对应的值,无论输入多少次,它必须与之前返回的一致。
它对不同的输入应映射到不同的数字,例:如果一个散列函数无论输入什么都返回1,则这不是一个好的散列函数。最理想的情况是,将不同的输入映射到不同的数字。
特点:
- 同样的时输入映射到相同的索引
- 不同的输入映射到不同的索引
- 只返回有效的索引
在 Javascript 中 Map 就是类似的内置对象,实现基础的散列表。
// 实现上面举例
class HashTable {
constructor() {
this.table = []
}
set(key, value) {
const index = this._computeIndex(key)
this.table[index] = value
}
get(key) {
const index = this._computeIndex(key)
return this.table[index]
}
// 这就相当于散列函数,但这个不是一个好的散列函数,很容易会照成冲突,这里只是为了展示
_computeIndex(key) {
return key.length
}
// 省略其他必要方法,如 移除,判断存在,返回长度等
}
const note = new HashTable()
note.set('apple', 10)
note.set('banana', 20)
console.log('苹果是', note.get('apple'), '元')
console.log('香蕉是', note.get('banana'), '元')
// 输出:
// 苹果是 10 元
// 香蕉是 20 元常见使用场景:
- 仿真映射关系,如:DNS 解析,域名映射ip。
- 防止重复,如:记录投过票的人的信息,用于判断是否可以投票(前提是每个用户只能投一次)
- 缓存
冲突
因为散列表需要根据不同的输入映射不同的值,但实际上我们是不可能编写出这样的散列函数的。我们只能尽可能避免冲突。
比如:举例的代码实现中,散列函数时根据商品名称的长度来分配位置的,当相同长度的商品再次出现,则会返回同样的位置,而那个位置已经有值保存着,则就会造成冲突。即给两个键分配的位置相同。后者会覆盖前者。(可以自行实践一下 Map)
解决冲突方法
- 优秀的散列函数
- 把键下映射的不再是一个值,而是一个链表。多个值通过链表的方式存储。
性能
散列表提高性能的方法就是避免冲突,编写一个良好的散列函数和较低的填充因子。
| 散列表(平均情况) | 散列表(最糟情况) | 数组 | 链表 | |
|---|---|---|---|---|
| 查找 | O(1) | O(n) | O(1) | O(n) |
| 插入 | O(1) | O(n) | O(n) | O(1) |
| 删除 | O(1) | O(n) | O(n) | O(1) |
散列表的查找速度很快,因为与数组一样,获取给定索引出的值。插入和删除与链表一样快。最糟情况则都很慢,如:刚才为了避免冲突使用了保存链表,如果链表很长则查询起来非常的慢。
填充因子就是 散列表包含的元素数 / 位置总数(数组长度)
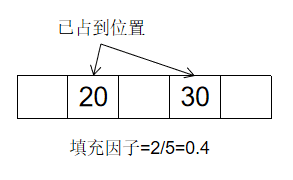
一旦填装因子开始增大,你就需要在散列表中添加位置,这被称为调整长度(即修改数组长度)。一般填装因子大于0.7,就调整散列表的长度。
注意:
Javascript不存在这种问题,因为数组会根据最大索引值自动增长。而 Java 等语言中声明数组时需要固定数组长度,且使用的时候不能超过数组的长度。